Hey! If you are a web developer, you should know about CatchJS. It’s a service for tracking and logging errors in JavaScript, with some pretty exciting features.

“F.D.R.’s War Plans!” reads a headline from a 1941 Chicago Daily Tribune. Had this article been written today, it might rather have said “21 War Plans F.D.R. Does Not Want You To Know About. Number 6 may shock you!”. Modern writers have become very good at squeezing out the maximum clickability out of every headline. But this sort of writing seems formulaic and unoriginal. What if we could automate the writing of these, thus freeing up clickbait writers to do useful work?
If this sort of writing truly is formulaic and unoriginal, we should be able to produce it automatically. Using Recurrent Neural Networks, we can try to pull this off.
How well can a neural network write clickbait? This screenshot is a hint.
Standard artificial neural networks are prediction machines, that can learn how to map some input to some output, given enough examples of each. Recently, as people have figured out how to train deep (multi-layered) neural nets, very powerful models have been created, increasing the hype surrounding this so-called deep learning. In some sense the deepest of these models are Recurrent Neural Networks (RNNs), a class of neural nets that feed their state at the previous timestep into the current timestep. These recurrent connections make these models well suited for operating on sequences, like text.

Left: RNNs have connections that form a cycle. Right: The RNN unrolled over three timesteps. By unrolling over time we can train an RNN like a standard neural network.
We can show an RNN a bunch of sentences, and get it to predict the next word, given the previous words. So, given a string of words like “Which Disney Character Are __”, we want the network to produce a reasonable guess like “You”, rather than, say, “Spreadsheet”. If this model can learn to predict the next word with some accuracy, we get a language model that tells us something about the texts we trained it on. If we ask this model to guess the next word, and then add that word to the sequence and ask it for the next word after that, and so on, we can generate text of arbitrary length. During training, we tweak the weights of this network so as to minimize the prediction error, maximizing its ability to guess the right next word. Thus RNNs operate on the opposite principle of clickbait: What happens next may not surprise you.
I based this on Andrej Karpathy’s wonderful char-rnn library for Lua/Torch, but modified it to be more of a “word-rnn”, so it predicts word-by-word, rather than character-by-character. (Code will be put up on github soon. Here is the code.) Predicting word-by-word will use more memory, but means the model does not need to learn how to spell before it learns how to perform modern journalism. (It still needs to learn some notion of grammar.) Some more changes were useful for this particular use case. First, each input word was represented as a dense vector of numbers. The hope is that having a continuous rather than discrete representation for words will allow the network to make better mistakes, as long as similar words get similar vectors. Second, the Adam optimizer was used for training. Third, the word vectors went through a particular training rigmarole: They received two stages of pretraining, and were then frozen in the final architecture – more details on this later in the article.
The final network architecture looked like this:
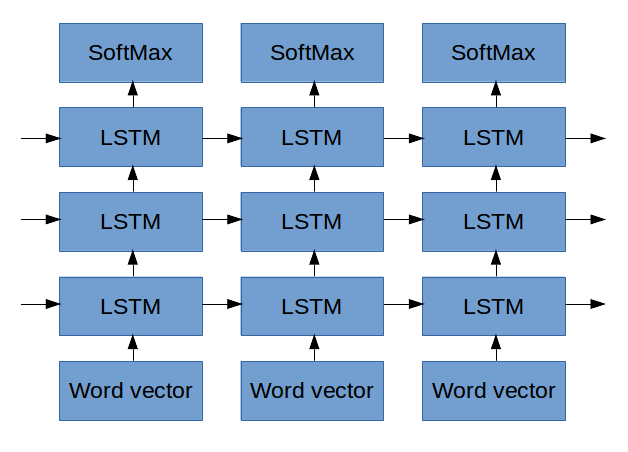
One Neat Trick Every 90s Connectionist Will Know
Whereas traditional neural nets are built around stacks of simple units that do a weighted sum followed by some simple non-linear function (like a tanh), we’ll use a more complicated unit called Long Short-Term Memory (LSTM). This is something two Germans came up with in the late 90s that makes it easier for RNNs to learn long-term dependencies through time. The LSTM units give the network memory cells with read, write and reset operations. These operations are differentiable, so that during training, the network can learn when it should remember data and when it should throw it away.
To generate clickbait, we’ll train such an RNN on ~2 000 000 headlines, scraped from Buzzfeed, Gawker, Jezebel, Huffington Post and Upworthy.
How realistic can we expect the output of this model to be? Even if it can learn to generate text with correct syntax and grammar, it surely can’t produce headlines that contain any new knowledge of the real world? It can’t do reporting? This may be true, but it’s not clear that clickbait needs to have any relation to the real world in order to be successful. When this work was begun, the top story on BuzzFeed was “50 Disney Channel Original Movies, Ranked By Feminism“. More recently they published “22 Faces Everyone Who Has Pooped Will Immediately Recognized“. It’s not clear that these headlines are much more than a semi-random concatenation of topics their userbase likes, and as seen in the latter case, 100% correct grammar is not a requirement.
The training converges after a few days of number crunching on a GTX980 GPU. Let’s take a look at the results.
Early on in the training, the model is stringing together words with very little over all coherency. This is what it produces after having seen about 40000 headlines:
Adobe ‘ s Saving New Japan
Real Walk Join Their Back For Plane To French Sarah York
State 7
Dr 5 Gameplay : Oscars Strong As The Dead
Economic Lessons To Actress To Ex – Takes A App
You ‘ s Schools ‘ : A Improve Story
However, after having had multiple passes through the data, the training converges and the results are remarkably better. Here are its first outputs after completed training:
Earth Defense Force : Record Olympic Fans
Kate Middleton , Prince William & Prince George Leave Kate For The Queen
The Most Creative Part Of U . S . History
Biden Responds To Hillary Clinton ‘ s Speech
The Children Of Free Speech
Adam Smith And Jennifer Lawrence ( And Tiger Woods ” Break The Ice Ball , For This Tornado )
Romney Camp : ‘ I Think You Are A Bad President ‘
Here ‘ s What A Boy Is Really Doing To Women In Prison Is Amazing
L . A . ‘ S First Ever Man Review
Why Health Care System Is Still A Winner
Why Are The Kids On The Golf Team Changing The World ?
2 1 Of The Most Life – Changing Food Magazine Moments Of 2 0 1 3
More Problems For ‘ Breaking Bad ‘ And ‘ Real Truth ‘ Before Death
Raw : DC Helps In Storm Victims ‘ Homes
U . S . Students ‘ Latest Aid Problem
Beyonce Is A Major Woman To Right – To – Buy At The Same Time
Taylor Swift Becomes New Face Of Victim Of Peace Talks
Star Wars : The Old Force : Gameplay From A Picture With Dark Past ( Part 2 )
Sarah Palin : ‘ If I Don ‘ t Have To Stop Using ‘ Law , Doesn ‘ t Like His Brother ‘ s Talk On His ‘ Big Media ‘
Israeli Forces : Muslim – American Wife ‘ s Murder To Be Shot In The U . S .
And It ‘ s A ‘ Celebrity ‘
Mary J . Williams On Coming Out As A Woman
Wall Street Makes $ 1 Billion For America : Of Who ‘ s The Most Important Republican Girl ?
How To Get Your Kids To See The Light
Kate Middleton Looks Into Marriage Plans At Charity Event
Adorable High – Tech Phone Is Billion – Dollar Media
Tips From Two And A Half Men : Getting Real
Hawaii Has Big No Place To Go
‘ American Child ‘ Film Clip
How To Get T – Pain
How To Make A Cheese In A Slow – Cut
WATCH : Mitt Romney ‘ s New Book
Iran ‘ s President Warns Way To Hold Nuclear Talks As Possible
Official : ‘ Extreme Weather ‘ Of The Planet Of North Korea
How To Create A Golden Fast Look To Greece ‘ s Team
Sony Super Play G 5 Hands – On At CES 2 0 1 2
1 5 – Year – Old , Son Suicide , Is Now A Non – Anti
” I ” s From Hell ”
God Of War : The World Gets Me Trailer
How To Use The Screen On The IPhone 3 Music Player
World ‘ s Most Dangerous Plane
The 1 9 Most Beautiful Fashion Tips For ( Again ) Of The Vacation
Miley Cyrus Turns 1 3
This Guy Thinks His Cat Was Drunk For His Five Years , He Gets A Sex Assault At A Home
Job Interview Wins Right To Support Gay Rights
Chef Ryan Johnson On ” A . K . A . M . C . D . ” : ” ” They Were Just Run From The Late Inspired ”
Final Fantasy X / X – 2 HD : Visits Apple
A Tour Of The Future Of Hot Dogs In The United States
Man With Can – Fired Down After Top – Of – The – Box Insider Club Finds
WATCH : Gay Teens Made Emotional Letter To J . K . Williams
It surprised me how good these headlines turned out. Most of them are grammatically correct, and a lot of them even make sense.
Consider the sentence “Mary J. Williams On Coming Out As A Woman”. I suspected this might be a case where the network had simply memorized a headline from the dataset. It turns out this was not the case. The only thing similar to “Coming Out As A Woman” is the headline “Former Marine Chronicles Journey Coming Out As A Trans Woman On YouTube”. The name “Mary J. Williams” does not appear in the dataset. The network has apparently learned that this is a plausible name, and also that such a name is the type of thing that can come out as a woman.
Another good one is “Romney Camp: ‘I Think You Are A Bad President'”. It’s suspiciously good – it wouldn’t surprise me if this was a real headline that some website had published. But it’s not in the dataset, not even close. While “Romney Camp” occurs 17 times in the dataset, none of these contain any statement about the president (or even the word president). “Bad President” occurs only once in the dataset, in the headline “Rubio: Obama Is A ‘Bad President'”. Yet, the network knows that the Romney Camp criticizing the president is a plausible headline. The network knows something about language, and it has some level of knowledge about the world by knowing what words are semantically associated.
Kim Kardashian Is Married With A Baby In New Mexico
Let’s investigate these semantic associations. By seeding the model with the start of a sentence, and getting the RNN to complete it, we can get a peek into what the model knows. For example, we can ask it to complete “Barack Obama Says” and “Kim Kardashian Says”, and compare the outputs.
Here are the 10 first completions of “Barack Obama Says”:
Barack Obama Says He’s Like ‘A Single Mother’ And ‘Over The Top’
Barack Obama Says He Is “The First Threat Gay Woman In The World”
Barack Obama Says About Ohio Law
Barack Obama Says He Is Wrong
Barack Obama Says He Will Get The American Idol
Barack Obama Says Himself Are “Doing Well Around The World”
Barack Obama Says As He Leaves Politics With His Wife
Barack Obama Says He Did 48 Things Over
Barack Obama Says GOP Needs To Be Key To New Immigration Policy
And here are the 10 first completions of “Kim Kardashian Says”:
Kim Kardashian Says ‘Idea’ To Her Mean Baby!
Kim Kardashian Says North West Is Even More ‘Important’
Kim Kardashian Says She Would Love Kanye
Kim Kardashian Says She’s A Hero
Kim Kardashian Says She Looks Fake
Kim Kardashian Says It Was Over Before They Call Her
Kim Kardashian Says Her Book Used To Lose Her Cool
Kim Kardashian Says She’s Married With A Baby In New Mexico
Kim Kardashian Says Kanye West Needs A Break From Her
Question Answering
By getting the RNN to complete our sentences, we can effectively ask questions of the model. Ilya Sutskever and Geoff Hinton trained a character level RNN on Wikipedia, and asked it to complete the phrase “The meaning of life is”. The RNN essentially answered “human reproduction”. It’s funny that you can get an RNN to read Wikipedia for a month, and have it essentially tell you that meaning of life is to have sex. It’s probably also a correct answer from a biological perspective.
We can’t directly replicate this experiment on the clickbait model, because the word “meaning” is not in its vocabulary. But we can ask it to complete the phrase “Life Is About”, for similar effect. These are the first 10 results:
Life Is About The (Wild) Truth About Human-Rights
Life Is About The True Love Of Mr. Mom
Life Is About Where He Were Now
Life Is About Kids
Life Is About What It Takes If Being On The Spot Is Tough
Life Is About A Giant White House Close To A Body In These Red Carpet Looks From Prince William’s Epic ‘Dinner With Johnny’
Life Is About — Or Still Didn’t Know Me
Life Is About… An Eating Story
Life Is About The Truth Now
Network details
With some experimentation, I ended with the following architecture and training procedure. The initial RNN had 2 recurrent layers, each containing 1200 LSTM units. Each word was represented as a 200 dimensional word vector, connected to the rest of the network via a tanh. These word vectors were initialized to the pretrained GloVe vectors released by its inventors, trained on 6 billion tokens from Wikipedia. GloVe, like word2vec, is a way of obtaining representations of words as vectors. These vectors were trained for a related task on a very big dataset, so they should provide a good initial representation for our words. During training, we can follow the gradient down into these word vectors and fine-tune the vector representations specifically for the task of generating clickbait, thus further improving the generalization accuracy of the complete model.
It turns out that if we then take the word vectors learned from this model of 2 recurrent layers, and stick them in an architecture with 3 recurrent layers, and then freeze them, we get even better performance. Trying to backpropagate into the word vectors through the 3 recurrent layers turned out to actually hurt performance.

To summarize the word vector story: Initially, some good guys at Standford invented GloVe, ran it over 6 billion tokens, and got a bunch of vectors. We then took these vectors, stuck them under 2 recurrent LSTM layers, and optimized them for generating clickbait. Finally we froze the vectors, and put them in a 3 LSTM layer architecture.
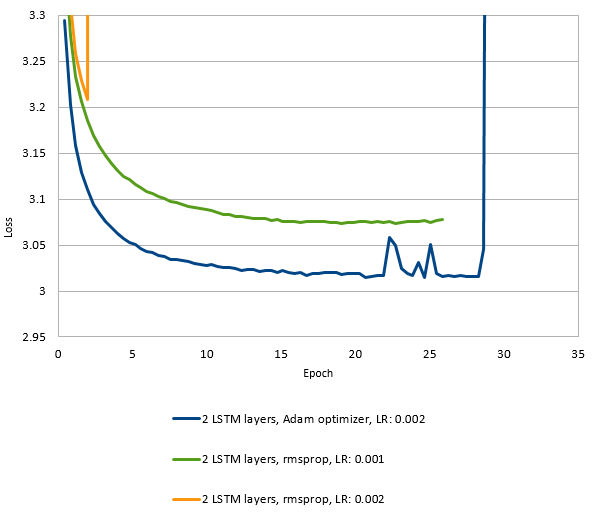
The network was trained with the Adam optimizer. I found this to be a Big Deal: It cut the training time almost in half, and found better optima, compared to using rmsprop with exponential decay. It’s possible that similar results could be obtained with rmsprop had I found a better learning and decay rate, but I’m very happy not having to do that tuning.
Building The Website
While many headlines produced from this model are good, some of them are rambling non-sense. To filter out the non-sense, we can do what Reddit does and crowd source the problem.
To this end, I created Click-o-Tron, possibly the first website in the world where all articles are written in their entirety by a Recurrent Neural Network. New articles are published every 20 minutes.

Any user can vote articles up and down. Each article gets an associated score determined by the number of votes and views the article has gotten. This score is then taken into account when ordering the front page. To get a trade-off between clickbaitiness and freshness, we can use the Hacker News algorithm:
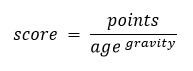
In practice, this can look like the following in PostgreSQL:
CREATE FUNCTION hotness(articles) RETURNS double precision LANGUAGE sql STABLE AS $_$ SELECT $1.score / POW(1+EXTRACT(EPOCH FROM (NOW()-$1.publish_date))/(3*3600), 1.5) $_$;
The articles are a result of three seperate language models: One for the headlines, one for the article bodies, and one for the author name.
The article body neural network was seeded with the words from the headline, so that the body text has a chance to be thematically consistent with the headline. The headlines were not used during training.
For the author names, a character level LSTM-RNN was trained on a corpus of all first and last names in the US. It was then asked to produce a list of names. This list was then filtered so that the only remaining names were the ones where neither the first nor the last name was in the original corpus. This creates a nice list of plausible, yet original names, such as Flodrice Golpo and Richaldo Aariza.
Finally, each article’s picture is found by searching the Wikimedia API with the headline text, and selecting the images with a permissive license.
In total, this gives us an infinite source of useless journalism, available at no cost. If I remember correctly from economics class, this should drive the market value of useless journalism down to zero, forcing other producers of useless journalism to produce something else.
As they say on BuzzFeed: Win!

Are you using the upvotes to influence the training for the articles/headlines?
Haha, this is AWESOME!
Rudolf Olah: Not currently 🙂
This is an amazing idea, well done. I think you might need some Cloudflare on the Click-o-Tron!
Very cool! If you need an infinite (sort of 🙂 supply of source input you can use the random clickbait headline generator: http://phrasegenerator.com/headlines
Thanks for the article! Any chance of sharing the code?
I fed megahal all of Lewis Carroll’s works from project Gutenberg, and after a little chat it suggested “What is the use of computers without pictures or conversation”.
Very noticeable that it learnt good grammar from Lewis and bad grammar from my chats.
Might be worth comparing megahal, but uses very similar method.
I also used a grammar tool to generate snow clones for t-shirt slogans. Basically you break down your examples into noun, verb, adverb, preposition, phrase, and offer it substitutes for each. Would think for the formulaic click bait it would work better but requires a bit more input. How I hit the slogans, “what would RMS do”.
All mine was done with free software, so just what RMS would do. Happy hacking 😉
Did you have any issues with overfitting? And, if so, how did you address them?
This is awesome! Hilarious (and fascinating) idea, great post.
But I think you might have forgotten to close a filehandle somewhere in Clickotron:
Error: 500 Internal Server Error
Sorry, the requested URL ‘http://clickotron.com/’ caused an error:
Internal Server Error
Exception:
IOError(24, ‘Too many open files’)
@Xerxes: Yup, I’ll be sharing the code within a few days. I got busy setting up a proper server for clickotron.com, and now I need sleep.
sf: Yes, I used 30% dropout between the LSTM layers to deal with overfitting.
Thanks!
I can’t understand the first two layer RNN which optimized the word vectors.
how to you follow the gradient down into these word vectors?
if word vectors are the input of the network, don’t we only train the weight of the network? how come the input vectors get optimized during the process?
*goes off to work on clickbait generator API*
hahahaha: The parameters in the word vectors are optimized the same way as every other parameter in the network: Using the rate of change of the error function with respect to the parameter. You’re right that they’re strictly speaking not inputs, but part of the network. In that view it’s really the index of the word vector that’s the input to the network.
$1 isn’t that dynamic SQL? Don’t do that.
I see you’re hosting clickotron.com on a Linode and its IPv6 is already active. Please add an AAAA record so this wonderful work is available on the modern Internet. Thanks!
A fellow developer here pointed out that this article title is pretty much clickbait for devs 🙂
hi larseidnes,
Thank you. I understand word2vec. you use word index as input and you train the network to get a dense representation. but I still can’t see how lstm is used to do the same thing.
I still can’t understand the first network. what are the inputs, what are the outputs and what are the labels. eventually when the network converge how new word vectors are derived from the network’s weight.
looking forward to seeing the source code and then I may be able to understand.
Hi
nice share and very cool. I am confused about how to generate first word of your RNN abstract. and Given we have an article with several paragraphs, how does the RNN code generate its abstract of the article. I want to know details in predicting or generating an article’s abstract.
thank you very much
So what would be really fun would be a site that would aitogenerate click bait headlines based on a block of blog text. In a truly recursive “art imitates life imitates art” kind of way you’d probably get authors from buzzfeed, gawker, huffpo, and so on to use the tool they trained
“A Tour Of The Future Of Hot Dogs In The United States”
I would totally read that article.
The code is now up on https://github.com/larspars/word-rnn
hahahaha: There really is nothing special about the word vectors are trained, they are trained like every other parameter in the net. I think a good place to start are the lecture videos available here: http://cs224d.stanford.edu/syllabus.html He goes through an example of an LSTM-RNN with word vector inputs in there, though I don’t remember which lecture. I’ve also published the code now, so that should help
vepniz: A seperate model was trained on article bodies, and this was seeded with words from the headline. I.e. it was told to make a completion of the headline text. One complication is that the artice model and headline model had different vocabularies, so seed words had to be in both vocabularies.
What is your twitter handle?
This is very reminiscent of a Stanislaw Lem short story called “137 seconds”.
Did you use that technique for this topics headline as well? 😛
It sounded like you were describing Markov chains in the first half of your article. How is RNN different than Markov chains?
On http://clickotron.com/article/5821/12-awesome-ways-to-drink-like-a-boss I got & mdash;, and it appears that some HTML entities are learnt by some mistake. It will definitely look better if the text goes like WASHINGTON —
Impressive. Thanks for this great demo.
I read “How To Get Your Kids To See The Light” but wasn’t enlightened. I must be too old haha
I’m guessing your next step is to try and improve the article’s quality by keeping the headline keywords as “fixed input” (what’s the word for that technique again?) while training / sampling on top of priming with the headline. Since you went the trouble to go away from character-based, and you’re hinting at it too. Perhaps mix in your input corpus some articles from better sources to add a bit of literacy; I mean since it’s going to be generally nonsensical perhaps you could father a new poetric dadaist tabloid genre, automatically parodied from the current trends?
Then when you reach the point where it’s fun to click around in its own right and come back later to check out the trend changes, add an automatic context-based fake ad generator too. Obviously people will want to click on those to have fun with the details of the automated ad too.
At this point you have context info that lets you market real targeted ads and make lots of $$$!
(I’m releasing this business plan under whatever license let me get 1% of the revenue thank you very much)
LOL
Next step: Throw each headline into twitter/facebook/G+/GNU social/whatever and just use the click-count to optimize the article generation. Or, well, putting Google ads on it and using the ad statistics to optimize the RNN ← just moved from being a journalist to being a low-quality newspaper ☺
One of the current headlines on Click-a-Tron: “Miley Cyrus Turns 13”
I honestly cannot contain my hysterical laughter!
This is awesome
It would be nice if you could give a link to the Wikimedia image you chose to illustrate the article — this is also a way to discover semi-random interesting content. Note that, for images whose license requires to give attribution information, you have to do a bit more: credit the author and indicate which license is used. I believe that the way images are currently embedded in your website (with no mention of their author) does not respect the licenses; for example, the image of

http://clickotron.com/article/5595/how-the-worlds-most-extreme-baby-moms-lost-weight
comes from
which is licensed under CC-BY-SA, so the article must give attribution information.
(I put the wrong link to Wikimedia by mistake, the correct one should be https://commons.wikimedia.org/wiki/File:Bundesarchiv_B_145_Bild-F002449-0003,_Bonn,_Bundestag,_Pariser_Vertr%C3%A4ge,_Mommer.jpg )
Is this a typo? “First, each input input word was represented” I think it would read better with just one occurrence of “input”.
I’ve been browsing online more than 4 hours today, yet I never found any
interesting article like yours. It is pretty
worth enough for me. In my opinion, if all site owners and bloggers made good content as
you did, the internet will be a lot more useful than ever before.
Sean Moore Gonzalez: I’m not on Twitter at the moment.
Rick: First order Markov chains only take into account the single past word, while RNNs can take into account amuch longer history. This should make the predicted sentences better, and means the network can balance quotes and parenthesis, etc.
gasche: There actually is attribution if you look under the image. It’s light text on a light background – perhaps it’s not as clear on all monitors.
Mingye Wang: Good catch! A result of imperfectly cleaning the training data.
JML34: Good idea, maybe one could condition each word in the article network on the final activation pattern (sentence vector) of the headline network.
Aaron Schumacher: Yup, that would be a typo, good catch!
Love this algorithmic advanced nonsense. And yes, definitely getting the article text to relate to the headline would be a great idea.
Hmm for some reason I thought this was _your_ idea to begin with.
Perhaps because I was hoping you’d implement it and I’d get to see the result ^^
Also you’re not saying “I first tried char-rnn but it failed in this and that way so I modified it to use dense words”. It’s not obvious that char-wise should fail (learning to spell is quick, it makes interesting mistakes too, plus it would come up with random names for free), unless you tried. But it’d be weird to try to condition with a string of chars; these vecs look a lot more promising.
I agree it looks like the mistakes should be more interesting. It would be interesting to compare the results of both approaches.
@gnufan: I’m preprocessing the 5 volumes of The Hitchhiker’s Guide to the Galaxy to feed megahal with (26k+ lines of text, so it’s taking a while). Let you know how it goes, if you’re interested. Maybe Stanislav Lem works follow, it can be funny, I think.
Please please make a taboo on-line game in which you can choose players such as Oliver Sacks, Richard Feynman, Francis Click, Patricia Churchland ect..
This is awesome. Any chance Click-o-Tron can get a Twitter handle???!
Joseph: It does now, at @clickotron_com
You only talked about that you used a GTX980, I would really like to know more about the hardware setup that you used.
@Josh: I don’t think there’s much to say about my setup though. Run time is dominated by GPU speed, so I think CPU speed is relatively unimportant. It’s also preferable to have a bit more RAM than you have GPU memory. That said, this is a nice hardware guide for deep learning: http://timdettmers.com/2015/03/09/deep-learning-hardware-guide/
What exact hyperparameters did you use? The default values in the code are from the character model, right?
30% dropout, learning rate left at the default (0.002), otherwise as described under “Network details”.
Great freakin article and thanks so much for turning me onto Glove!
clickotron doesn’t generate new stories anymore. Could you fix that, please?
Death to this BS – install adblock, unclick “allow some adverts”
good article,but need some help to learn about clickbait http://pressnews247.com
Great work! Thanks for your idea and efforts very much! I’m just wondering whether you could publicize the scraped news title dataset so we can operate on it too! Thanks if you could give me some information!
I see you don’t monetize your website, don’t waste your
traffic, you can earn additional bucks every month because you’ve got high quality
content. If you want to know how to make extra $$$, search for:
Ercannou’s essential adsense alternative